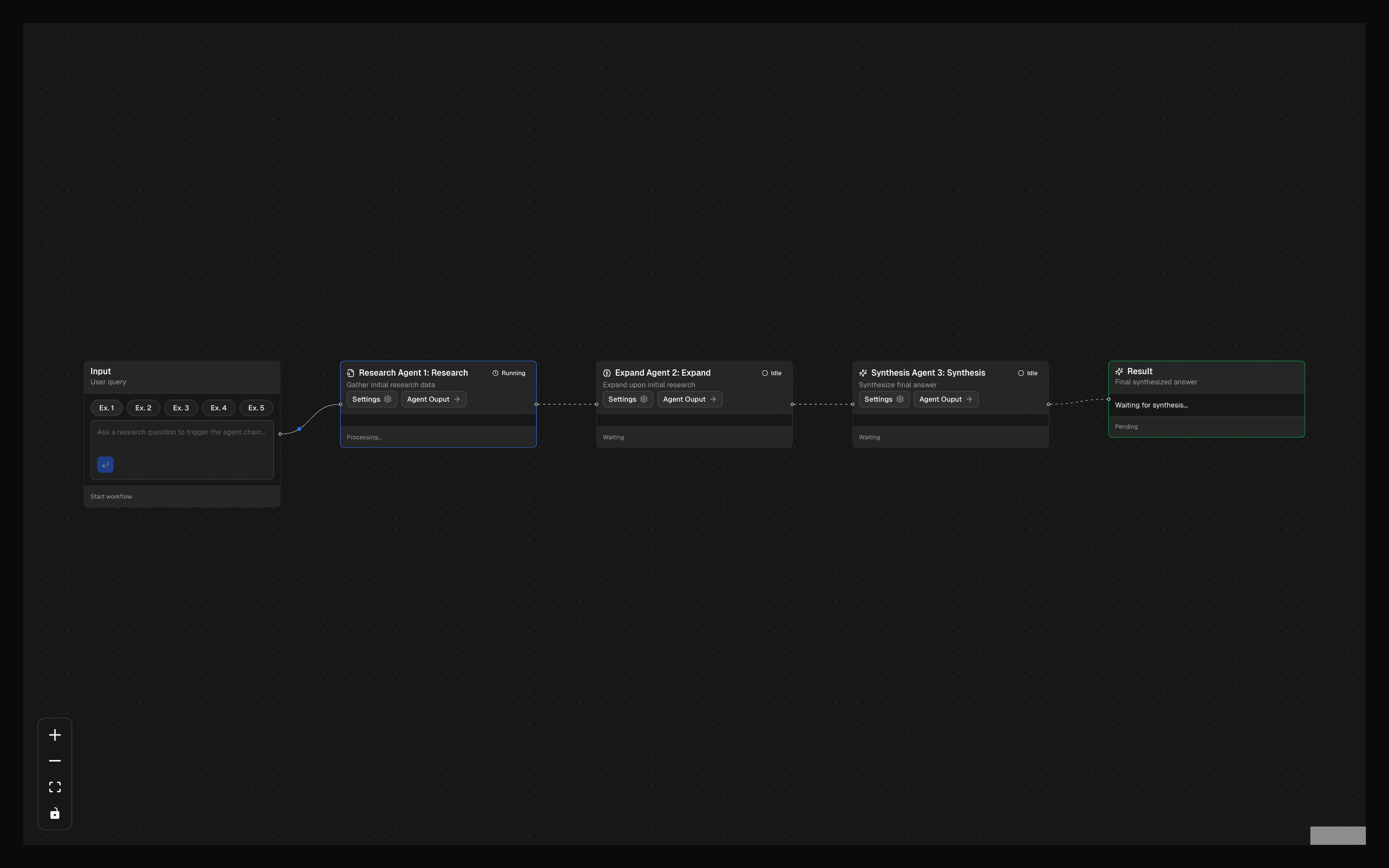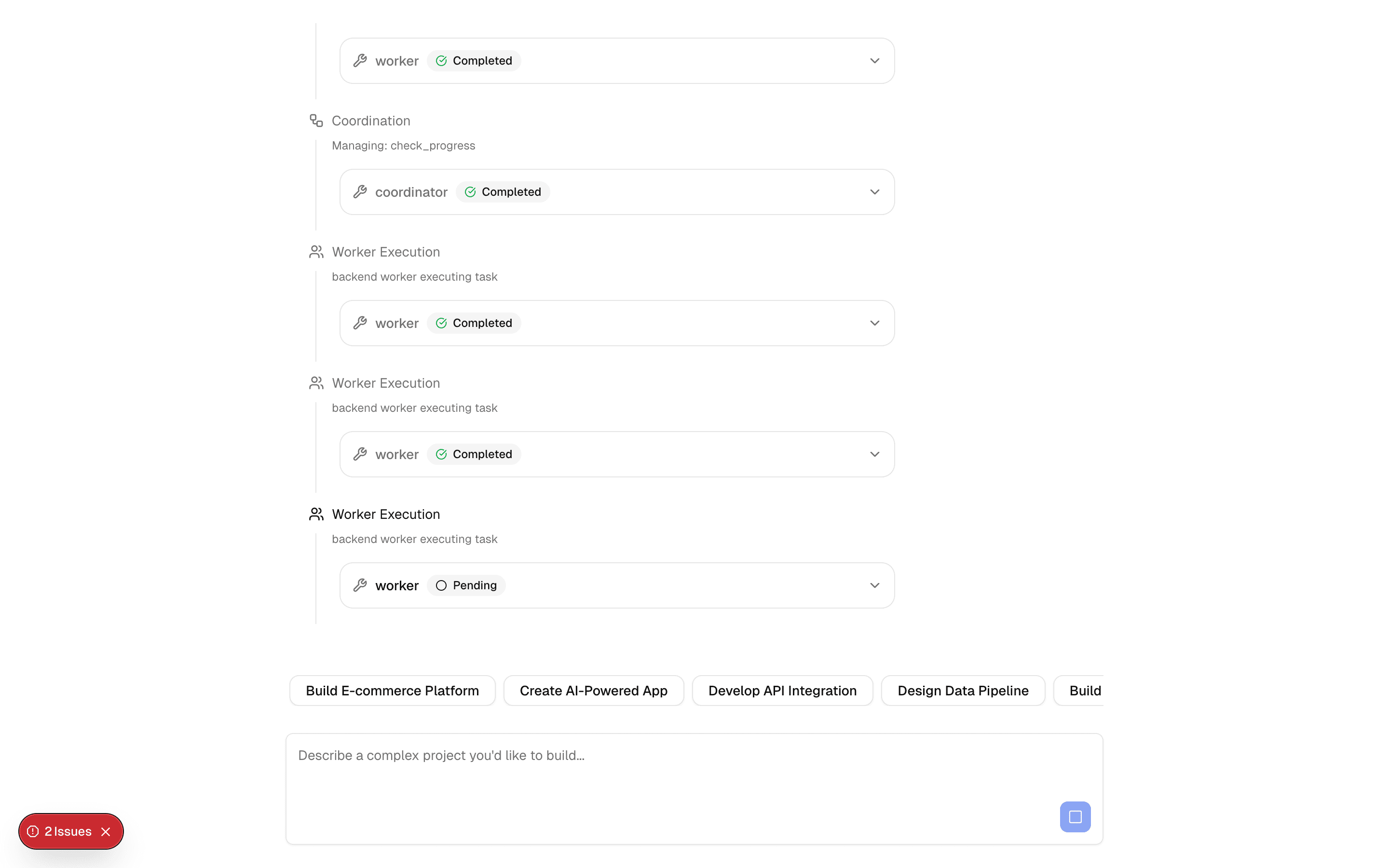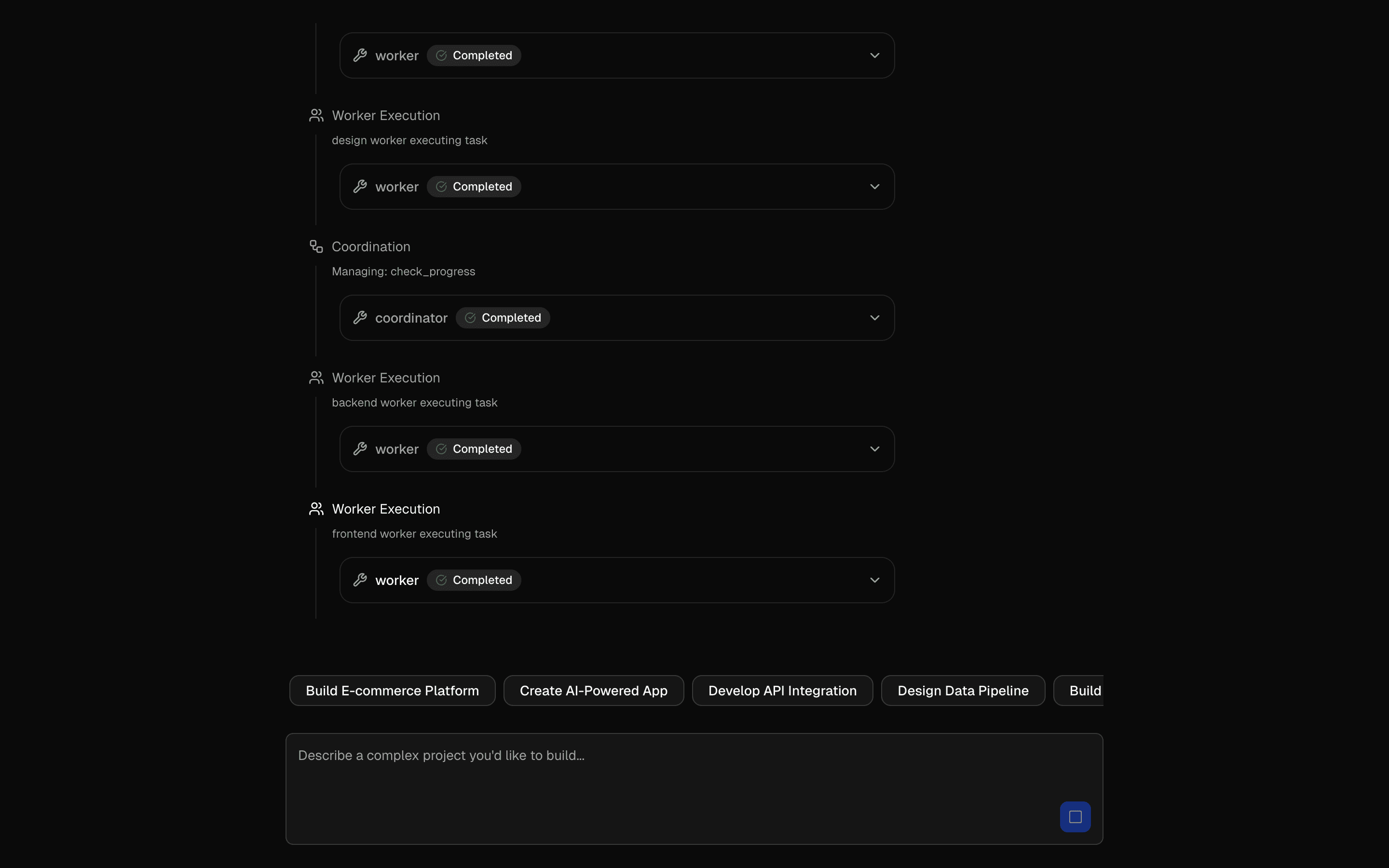
generateText is the foundational building block of the AI SDK — it sends a prompt to a language model and returns the complete response as a string. No streaming, no tool calling, no agent loops. Just prompt in, text out.
The function takes a model instance (from any provider — OpenAI, Anthropic, Google, etc.) and a prompt configuration. It returns a typed result object containing the generated text, token usage statistics, and metadata about the generation. The entire response is available at once, making it ideal for server-side processing where you need the complete output before continuing.
Under the hood, generateText handles provider-specific API differences, retry logic, and error normalization. You write one function call; the SDK handles the HTTP request, response parsing, rate limit retries, and type conversion for whichever provider you are using.
This is the right starting point for any AI integration. Once you understand generateText, every other SDK function is a variation on this pattern — streamText adds streaming, generateObject adds structured output, and agent() adds tool loops. Master this function first.